
Introduction to Natural Language Processing (NLP)
Introduction
Modern day Natural Language Processing, or NLP for short, is the computer manipulation and processing of any natural language that is used as a primary form of communication by humans. This is to include languages like English, Hindi, Mandarin, etc. This does not include 'languages' in terms of programming like python or matlab and does not include mathematical languages and notations. The extent of what encompasses this field ranges from tasks as simple as counting word frequencies to tasks as complicated as the computer understanding and forming a response to a query. Some example use cases that use NLP are predictive text writing, search engines, machine translation, and category tagging of word based social media. Chat-GPT, Bard, and LLAMA are all prime examples of what NLP can achieve in some of the most complicated and expansive models generated today.
Terminology
These are some common terms used when talking about NLP and what they mean:
Tokens
In natural language, each word or phrase of words has a specific meaning. In NLP, to begin understanding what the text means the first step is tokenization. This is the process of creating tokens of characters which could be individual words or phrases that have known meanings to the NLP model. If you program python in an integrated development environment for example, every time you type "import" you'll notice the word gets highlighted, this is a form of NLP and tokenization. Tokenization and tokens are used to help the model begin to interpret and structure a given phrase or blob of text. The big picture overview is instead of trying to understand a paragraph all at once, it starts with words it knows, then to sentences, then to the whole paragraph and this is all done on top of tokenization.
Corpus
A corpus in NLP is a text dataset that can be used to test against a model. These datasets are often used to aid in model training and machine translation.
Language Models
Language Models are trained to predict the next word (token) in a sentence.
Tasks:
- Speech Recognition
- Translation
- Text Generation
- Optical Character Recognition
- Information Retrieval
- Etc.
Modern Language Models are trained using self-supervised learning. This means that large amounts of unlabeled data can be used.
Once the initial training is complete, Transfer Learning can be used to specialize the model in a specific task.
Additionally, Fine Tuning) can be used to to specialize the model in a specific type of text (corpus).
Examples: reviews, news articles, social media communication, wikipedia
Table of contents
Todays blog will introduce the user to the following workflows, tools and NLP concepts:
- spaCy
- Vocabulary in NLP
- Tokenization
- Parts of Speech Tagging and Dependency Parsing
- Named Entity Recognition
- Morphology
- Sentence Recognition
- Word Simularity
- Practical Example
spaCy
spaCy is an open-source (MIT) python library for Natural Language Processing.
Features:
- Trained pipelines for 25 languages
- Transformer model support
- Prioritizes speed and production deployment
- NLP Components: Named Entity Recognition, Part-of-Speech Tagging, Dependency Parsing, Sentence Segmentation, Text Classification, Lemmatization, Morphological Analysis, Entity Linking
- Extensible
- Visualization tools
- Model packaging, deployment, and workflow management
Processing Pipelines
spaCy Language Processing Pipelines are used to perform NLP tasks and they can be trained, modified, and customized.

NLP Concepts Explained by Example:
Setup
##########################
# This code is adapted from https://spacy.io/usage/
##########################
!pip install -U pip setuptools wheel ipywidgets
!pip install -U 'spacy[apple]' # Remove [apple] if not using a M1/M2 Macbook (arm64)
!python -m spacy download en_core_web_sm
!python -m spacy download en_core_web_mdVocabulary
In NLP it is much easier for a computer to refer to numbers in memory than letters. Because of this, Machine Learning models use a vocabulary to convert each unique word (or part of a word for complex words) in the data to a number and all processing is done using these numbers. After processing is complete, the results can be converted back into words for human consumption.
spaCy uses hashes instead of a sequence of numbers so the vocabulary can be easily reproduced.
##########################
# This code is adapted from https://spacy.io/api/vocab
##########################
import spacy
nlp = spacy.load('en_core_web_sm')
print(nlp.vocab.strings["apple"])
print(nlp.vocab.strings['banana'])
print()
print(f'Number of tokens in vocabulary: {len(nlp.vocab.strings)}')8566208034543834098
2525716904149915114
Number of tokens in vocabulary: 84780Tokenizer
The tokenizer converts text into meaningful segments of text. These can be full words or multiple tokens may be used to represent complex words. Words, punctuation, and whitespace are all represented in the conversion process.
##########################
# This code is adapted from https://spacy.io/usage/linguistic-features#tokenization
##########################
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Ascolta is a U.S. based information technology company.")
for token in doc:
print(token.text)Ascolta
is
a
U.S.
based
information
technology
company
.Part-of-Speech Tagger/Dependency Parsing
Part-of-Speech Tagging predicts which words are nouns, verbs, proper nouns, adjectives, etc.
Dependency Parsing recognizes sentence boundaries and determines which nouns are related to which parts of a sentence.
##########################
# This code is adapted from the following webpages:
# https://spacy.io/usage/linguistic-features#pos-tagging
# https://spacy.io/usage/linguistic-features#dependency-parse
##########################
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Ascolta is a U.S. based information technology company.")
displacy.render(doc, style="dep")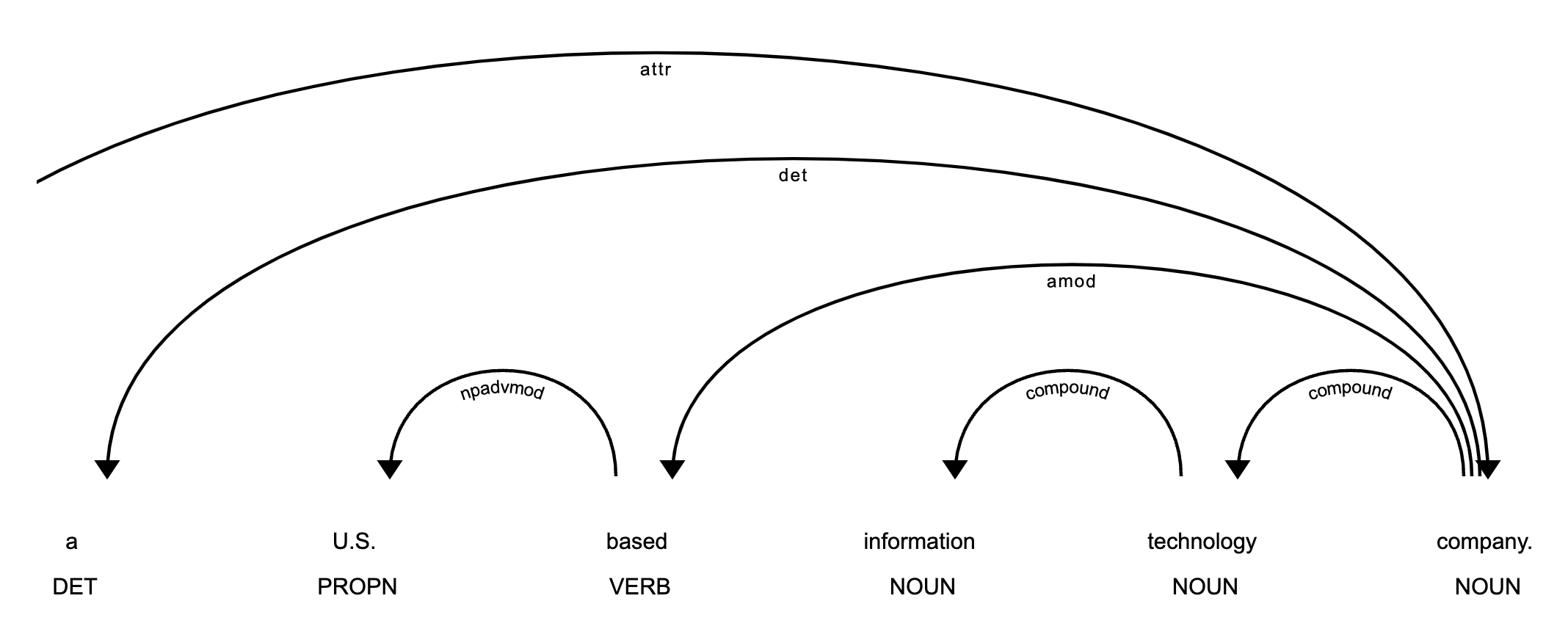
Named Entity Recognition
Named entity recognition parses text and makes a prediction about what type of entity a word could be. For example, organizations, dates, locations, and geopolitical entities.
##########################
# This code is adapted from https://spacy.io/usage/linguistic-features#named-entities
##########################
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("""Founded in 2014, Ascolta focuses on delivering Software development and design, DevOps and cloud migration services. We provide advanced technical services in the areas of information security, cloud management, adoption and migration. Ascolta develops and delivers system integration and professional services specializing in DevOps services that enable organizations to rapidly deploy solutions in the cloud or on premise.
Our DevOps heritage and extensive experience navigating the DoD Risk Management Framework (RMF) and DoD software testing and fielding processes help provide a sustainable solution to complex software problems.
In 2021, Ascolta was purchased by Ascolta’s staff and is now an employee owned and run company.
Ascolta has cleared staff who support numerous Department of Defense contracts as a fully DCAA compliant company.""")
displacy.render(doc, style="ent")Our DevOps ORG heritage and extensive experience navigating the DoD Risk Management Framework ORG ( RMF ORG ) and DoD GPE software testing and fielding processes help provide a sustainable solution to complex software problems.
In 2021 DATE , Ascolta ORG was purchased by Ascolta ORG ’s staff and is now an employee owned and run company.
Ascolta ORG has cleared staff who support numerous Department of Defense ORG contracts as a fully DCAA compliant company.
Morphology
Morphology processing determines the root form of words and how they are modified. For example, if a word is past tense or present tense.
##########################
# This code is adapted from https://spacy.io/usage/linguistic-features#morphology
##########################
import spacy
# English pipelines include a rule-based lemmatizer
nlp = spacy.load("en_core_web_sm")
lemmatizer = nlp.get_pipe("lemmatizer")
doc = nlp("I was reading a paper.")
print(f'Root word for "was" and "reading" are changed: {[token.lemma_ for token in doc]}')
print()
token = doc[1]
print(f'Get the word tense for "{token}": {token.morph.get("Tense")[0]}')Root word for "was" and "reading" are changed: ['I', 'be', 'read', 'a', 'paper', '.']
Get the word tense for "was": PastSentence Recognizer
The sentence recognizer is used to split words into sentences.
##########################
# This code is adapted from https://spacy.io/usage/linguistic-features#sbd
##########################
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is a sentence. This is another sentence.")
assert doc.has_annotation("SENT_START")
for sent in doc.sents:
print(sent.text)This is a sentence.
This is another sentence.Word Similarity
Word similarity is calculated using a Tok2Vec algorithm (also called Word2Vec). This algorithm represents words as vectors (numbers) and the closer two vectors are two eachother the more similar the compared words are.
When using this tool in spaCy a small model cannot be used. A medium or large model must be used instead.
##########################
# This code is adapted from https://spacy.io/usage/linguistic-features#vectors-similarity
##########################
import spacy
nlp = spacy.load("en_core_web_md") # make sure to use larger package!
doc1 = nlp("I like salty fries and hamburgers.")
doc2 = nlp("Fast food tastes very good.")
# Similarity of two documents
print(f'{doc1} <-> {doc2} {doc1.similarity(doc2):.2%}')
# Similarity of tokens and spans
french_fries = doc1[2:4]
burgers = doc1[5]
print(f'french_fries <-> burgers {french_fries.similarity(burgers):.2%}')I like salty fries and hamburgers. <-> Fast food tastes very good. 69.16%
french_fries <-> burgers 69.38%Practical Example
The following will demonstrate a simple use case combining some of the above tools.
- Extracting important words (nouns) from text
- Extracting subjects and objects of sentences from text
- Aggregating named entities
##########################
# This code is adapted from the following web pages:
# https://spacy.io/usage/linguistic-features#pos-tagging
# https://spacy.io/usage/linguistic-features#dependency-parse
# https://spacy.io/usage/linguistic-features#named-entities
##########################
from pprint import pprint
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("""Founded in 2014, Ascolta focuses on delivering Software development and design, DevOps and cloud migration services. We provide advanced technical services in the areas of information security, cloud management, adoption and migration. Ascolta develops and delivers system integration and professional services specializing in DevOps services that enable organizations to rapidly deploy solutions in the cloud or on premise.
Our DevOps heritage and extensive experience navigating the DoD Risk Management Framework (RMF) and DoD software testing and fielding processes help provide a sustainable solution to complex software problems.
In 2021, Ascolta was purchased by Ascolta’s staff and is now an employee owned and run company.
Ascolta has cleared staff who support numerous Department of Defense contracts as a fully DCAA compliant company.""")
print("Part-of-speech Analysis - Noun/Proper Noun\n")
nouns = []
for token in doc:
if token.pos_ in ["NOUN", "PROPN"]:
nouns.append(token)
print(set(nouns))
print("\n\n\n")
print("Part-of-speech Analysis/Dependency Labels - Subject/Object\n")
dependencies = []
for token in doc:
# Nominal Subject, Direct Object, Object of preposition
if token.dep_ in ["nsubj", "dobj", "pobj"]:
dependencies.append(token)
print(set(dependencies))
print("\n\n\n")
print("Named Entity Recognition\n")
entities = {}
for ent in doc.ents:
if ent.label_ in ['PERSON', 'DATE', 'EVENT', 'GPE', 'ORG']:
if ent.label_ not in entities.keys():
entities[ent.label_] = []
entities[ent.label_].append(ent.text)
# Remove Duplicates
for key in entities:
entities[key] = set(entities[key])
pprint(entities)Part-of-speech Analysis - Noun/Proper Noun
{migration, system, Ascolta, solutions, premise, cloud, Department, design, contracts, Software, Risk, services, services, company, processes, areas, testing, security, management, Ascolta, problems, Ascolta, staff, services, organizations, Ascolta, Ascolta, company, staff, heritage, experience, migration, Defense, DoD, DevOps, compliant, Framework, software, information, fielding, solution, cloud, software, adoption, integration, DevOps, services, employee, development, DevOps, DCAA, Management, cloud, DoD, RMF}
Part-of-speech Analysis/Dependency Labels - Subject/Object
{2021, that, solutions, premise, 2014, cloud, who, contracts, services, company, areas, security, Ascolta, problems, staff, services, organizations, Ascolta, Ascolta, company, staff, heritage, Defense, We, Framework, solution, integration, development}
Named Entity Recognition
{'DATE': {'2014', '2021'},
'GPE': {'DoD'},
'ORG': {'Ascolta',
'Department of Defense',
'DevOps',
'RMF',
'the DoD Risk Management Framework'}}